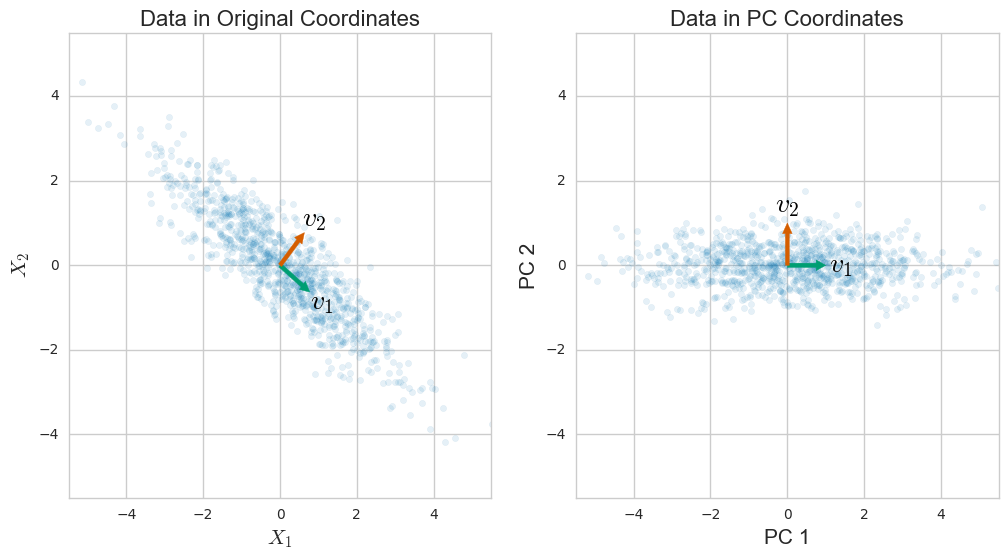
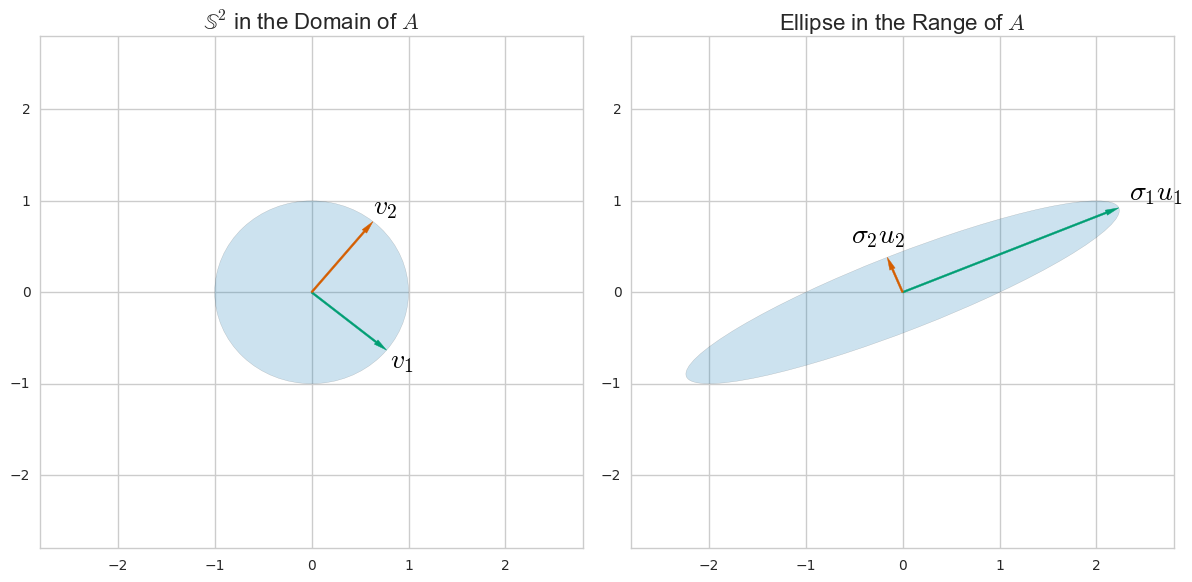
Анализ главных компонент (PCA) обычно объясняется с помощью собственного разложения ковариационной матрицы. Тем не менее, он также может быть выполнен с помощью сингулярного разложения (SVD) матриц данных . Как это работает? Какова связь между этими двумя подходами? Какая связь между СВД и СПС?
Или, другими словами, как использовать SVD матрицы данных для уменьшения размерности?
8
Я написал этот вопрос в стиле FAQ вместе со своим собственным ответом, потому что он часто задается в различных формах, но нет канонического потока, и поэтому закрытие дубликатов затруднительно. Пожалуйста, предоставьте мета-комментарии в этой мета-ветке .
—
амеба
В дополнение к превосходному и подробному ответу амебы с его дальнейшими ссылками, я мог бы рекомендовать проверить это , где PCA считается рядом с некоторыми другими методами, основанными на SVD. Здесь обсуждается алгебра, почти идентичная амебе, с небольшим отличием в том, что речь, описывающая PCA, идет о svd-разложении [илиX/ √ ] вместо X- что просто удобно, поскольку оно связано с PCA, выполняемым посредством собственного разложения ковариационной матрицы.
—
ttnphns
СПС является частным случаем СВД. PCA нужны нормализованные данные, в идеале это же устройство. Матрица nxn в PCA.
—
Орвар Корвар
@OrvarKorvar: О какой матрице nxn вы говорите?
—
Cbhihe