В своей работе по автоассоциатор для текста классификации Хинтон и Салахутдинов показал сюжет , полученный на 2-мерной LSA (который тесно связан с PCA) 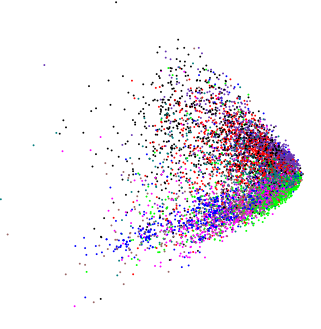 .
.
Применяя PCA к совершенно другим слегка многомерным данным, я получил похожий график:  (за исключением этого случая, я действительно хотел узнать, существует ли какая-либо внутренняя структура).
(за исключением этого случая, я действительно хотел узнать, существует ли какая-либо внутренняя структура).
Если мы подадим случайные данные в PCA, мы получим шарик в форме диска, поэтому эта клиновидная форма не случайна. Означает ли это что-нибудь само по себе?
6
Я предполагаю, что все переменные положительны (или неотрицательны) и непрерывны? Если это так, то края клина - это просто точки, за которыми данные станут 0 / отрицательными. Кроме того, вы можете получить тот же шаблон, который вы показываете с положительными перекошенными правыми переменными; наблюдения сгруппированы в нижней части. Если бы у вас были положительные однородные случайные величины, вы бы увидели (повернутый) квадрат. Следовательно, шаблоны, подобные тому, который вы показываете, являются просто ограничениями для данных. Другие шаблоны могут отображаться, как подкова, но это не связано с ограничениями диапазонов переменных.
—
Гэвин Симпсон
@GavinSimpson Это значительно больше, чем комментарий. Почему бы не развернуть это в ответ?
—
Майк Хантер
Я спросил своих детей (3 и 4 года), что им напоминают эти фотографии, и они сказали, что это рыба. Так что, возможно, "рыбоподобная форма"?
—
amoeba
@GavinSimpson, спасибо! В обоих случаях переменные действительно неотрицательны, но в обоих случаях они целочисленные. Это что-то меняет?
—
macleginn







