Это две разные метрики для оценки производительности вашей модели, которые обычно используются на разных этапах.
Потери часто используются в процессе обучения, чтобы найти «лучшие» значения параметров для вашей модели (например, веса в нейронной сети). Это то, что вы пытаетесь оптимизировать на тренировке, обновляя веса.
Точность больше с прикладной точки зрения. Как только вы найдете оптимизированные параметры выше, вы используете эти метрики, чтобы оценить, насколько точен прогноз вашей модели по сравнению с истинными данными.
Давайте использовать пример классификации игрушек. Вы хотите предсказать пол от своего веса и роста. У вас есть 3 данных, они следующие: (0 обозначает мужчину, 1 обозначает женщину)
y1 = 0, x1_w = 50 кг, x2_h = 160 см;
y2 = 0, x2_w = 60 кг, x2_h = 170 см;
y3 = 1, x3_w = 55 кг, x3_h = 175 см;
Вы используете простую модель логистической регрессии, которая имеет вид y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Как вы находите b1 и b2? сначала вы определяете потери и используете метод оптимизации, чтобы минимизировать потери итеративным способом, обновляя b1 и b2.
В нашем примере типичная потеря для этой двоичной задачи классификации может быть: (знак минус должен быть добавлен перед знаком суммирования)

Мы не знаем, какими должны быть b1 и b2. Давайте сделаем случайное предположение, скажем, b1 = 0,1 и b2 = -0,03. Тогда какова наша потеря сейчас?
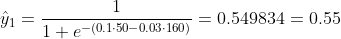
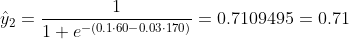
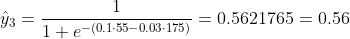
так что потеря
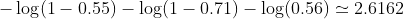
Затем вы изучите алгоритм (например, градиентный спуск), чтобы найти способ обновить b1 и b2, чтобы уменьшить потери.
Что, если b1 = 0,1 и b2 = -0,03 - это последние b1 и b2 (выходные данные градиентного спуска), какова точность сейчас?
Давайте предположим, что если y_hat> = 0.5, мы решаем, что наш прогноз женский (1). в противном случае это будет 0. Поэтому наш алгоритм предсказывает y1 = 1, y2 = 1 и y3 = 1. Какова наша точность? Мы делаем неправильный прогноз для y1 и y2 и делаем правильный прогноз для y3. Так что теперь наша точность составляет 1/3 = 33,33%
PS: В ответе Амира обратное распространение называется методом оптимизации в NN. Я думаю, что это будет рассматриваться как способ найти градиент для весов в NN. Распространенным методом оптимизации в NN являются GradientDescent и Adam.
