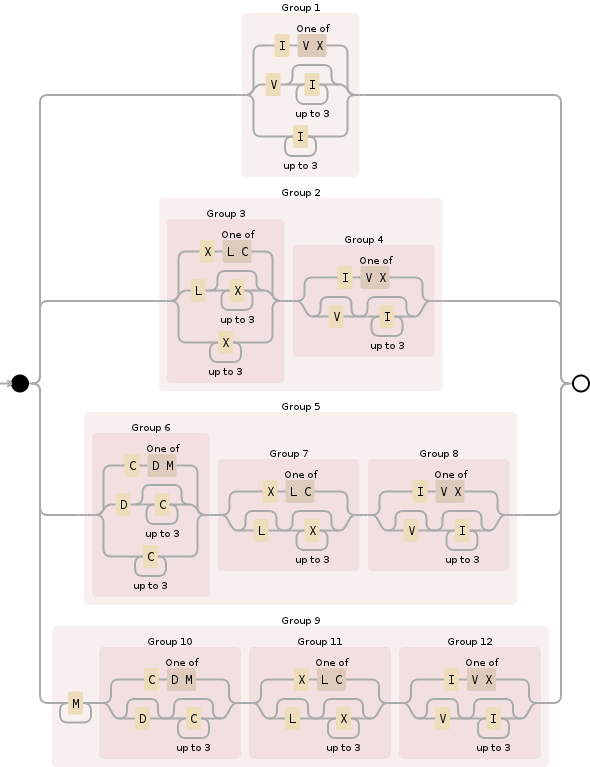
Для этого вы можете использовать следующее регулярное выражение:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Разбивая его, M{0,4}задает раздел тысяч и в основном ограничивает его между 0и 4000. Это относительно просто:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Конечно, вы можете использовать что-то вроде M*разрешения, чтобы разрешить любое число (включая ноль) тысяч, если вы хотите разрешить большее число.
Далее (CM|CD|D?C{0,3}), немного сложнее, это для сотен раздел и охватывает все возможности:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
В-третьих, (XC|XL|L?X{0,3})следует тем же правилам, что и в предыдущем разделе, но на десятом месте:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
И, наконец, (IX|IV|V?I{0,3})есть раздел единиц, обработка 0через 9и также похож на предыдущие две секций (римские цифры, несмотря на их кажущуюся странность, следуют некоторым логическим правилам , как только вы выяснить , что они есть):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Просто помните, что это регулярное выражение также будет соответствовать пустой строке. Если вы не хотите этого (и ваш движок регулярных выражений достаточно современен), вы можете использовать позитивный прогноз и прогноз:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(Другой вариант - просто проверить, что длина не равна нулю заранее).