У меня был этот вопрос в течение нескольких месяцев. Кажется, что мы просто хитро угадали softmax как выходную функцию, а затем интерпретировали входные данные softmax как логарифмические вероятности. Как вы сказали, почему бы просто не нормализовать все выходы путем деления на их сумму? Я нашел ответ в книге Гудфеллоу, Бенджо и Курвилля (2016) « Глубокое обучение» в разделе 6.2.2.
Допустим, наш последний скрытый слой дает нам z в качестве активации. Тогда softmax определяется как

Очень краткое объяснение
Выражение в функции softmax примерно аннулирует логарифмические потери в кросс-энтропии, в результате чего потеря является приблизительно линейной по z_i. Это приводит к примерно постоянному градиенту, когда модель ошибочна, что позволяет ей быстро исправляться. Таким образом, неправильный насыщенный softmax не вызывает исчезающий градиент.
Краткое объяснение
Самый популярный метод обучения нейронной сети - оценка максимального правдоподобия. Мы оцениваем параметры тета таким образом, чтобы максимизировать вероятность тренировочных данных (размером m). Поскольку вероятность всего обучающего набора данных является произведением вероятностей каждой выборки, проще максимизировать логарифмическую вероятность набора данных и, таким образом, сумму логарифмической вероятности каждой выборки, индексированной k:
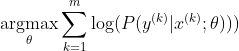
Теперь мы сконцентрируемся только на softmax с уже заданным z, поэтому мы можем заменить
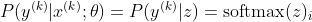
я являюсь правильным классом k-го образца. Теперь мы видим, что когда мы берем логарифм softmax, чтобы вычислить логарифмическую вероятность выборки, мы получаем:
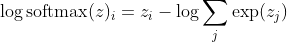
, что для больших различий в Z примерно приближается к
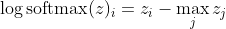
Сначала мы видим здесь линейную составляющую z_i. Во-вторых, мы можем исследовать поведение max (z) для двух случаев:
- Если модель верна, то max (z) будет z_i. Таким образом, логарифмическая правдоподобие асимптотически равна нулю (то есть вероятность 1) с растущей разницей между z_i и другими записями в z.
- Если модель неверна, то max (z) будет другим z_j> z_i. Таким образом, добавление z_i не полностью отменяет -z_j, и логарифмическая вероятность примерно равна (z_i - z_j). Это ясно говорит модели, что нужно сделать, чтобы увеличить логарифмическую вероятность: увеличить z_i и уменьшить z_j.
Мы видим, что в общем логарифмическом правдоподобии будут доминировать выборки, где модель неверна. Кроме того, даже если модель действительно неверна, что приводит к насыщенному softmax, функция потерь не насыщается. Это приблизительно линейно по z_j, что означает, что у нас есть приблизительно постоянный градиент. Это позволяет модели быстро исправить себя. Обратите внимание, что это не относится к среднеквадратичной ошибке, например.
Длинное объяснение
Если softmax все еще кажется вам произвольным выбором, вы можете взглянуть на обоснование использования сигмоида в логистической регрессии:
Почему сигмовидная функция вместо всего остального?
Softmax - обобщение сигмоида для мультиклассовых задач, обоснованное аналогично.



