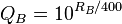У большинства наивных подходов к проблеме есть несколько серьезных недостатков. Хуже всего то, как bash.org и qdb.us отображают котировки: пользователи могут проголосовать за котировку вверх (+1) или вниз (-1), а список лучших цитат отсортирован по общему нетто-баллу. Это страдает от ужасной предвзятости во времени - старые цитаты собрали огромное количество положительных голосов благодаря простому долголетию, даже если они лишь отчасти юмористические. Этот алгоритм мог бы иметь смысл, если бы шутки становились смешнее с возрастом, но - поверьте мне - это не так.
Существуют различные попытки исправить это - посмотреть количество положительных голосов за период времени, взвесить более свежие голоса, внедрить систему убывания для старых голосов, вычислить соотношение положительных и отрицательных голосов и т. Д. Большинство из них страдают другими недостатками.
Лучшее решение - я думаю - это то, что используют сайты The Funniest The Cutest , The Fairest и Best Thing - модифицированная система голосования Кондорсе :
Система дает каждому номер, исходя из того, с чем он столкнулся, какой процент из них он обычно превосходит. Таким образом, каждый получает процентную оценку NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe). Кроме того, вещи исключаются из верхнего списка до тех пор, пока они не будут сравнены с разумным процентом набора.
Если в наборе есть победитель Кондорсе, этот метод найдет его. Поскольку это маловероятно, учитывая статистический характер, он находит тот, который «ближе всего» к победе по Кондорсе.
Для получения дополнительной информации о внедрении таких систем посетите страницу Википедии о ранговых парах. будет полезна .
Алгоритм требует, чтобы люди сравнивали два объекта (ваш вариант Pick-A-or-B), но, честно говоря, это хорошо. Я считаю, что в теории принятия решений очень хорошо принято, что люди намного лучше сравнивают два объекта, чем при абстрактном ранжировании. Миллионы лет эволюции делают нас хорошими в том, чтобы сорвать лучшее яблоко с дерева, но ужасно в том, чтобы решить, насколько близко яблоко, которое мы сорвали, отрублено к истинной платонической форме яблони. (Это, кстати, то, почему процесс аналитической иерархии такой изящный ... но это уже немного не по теме.)
Наконец, следует отметить, что SO использует алгоритм для поиска наилучших ответов, который очень похож на алгоритм bash.org для поиска наилучшей цитаты. Здесь он работает хорошо, но там ужасно не работает - в значительной степени потому, что старый, высоко оцененный, но теперь устаревший ответ здесь, вероятно, будет отредактирован. bash.org не позволяет редактировать, и непонятно, как бы вы вообще отредактировали анекдоты десятилетней давности об устаревших интернет-мемах, даже если бы могли ... В любом случае, я считаю, что правильный алгоритм обычно зависит от деталей вашей проблемы. :-)